 ← PostgreSQL Blog
← PostgreSQL Blog
What Happens When Your Only Data Center Goes Dark?
What Happens When Your Only Data Center Goes Dark?
“No one wants to lose the patient. But what if saving them is in your hands? This time, you’re the lifesaver.”
When it comes to database architecture, most decisions are made after something breaks and by then, it’s often too late. In this piece, we explore two real-world-inspired scenarios to demonstrate how PostgreSQL-based systems can be designed for high availability and disaster recovery. From a simple, single data center setup for a small business to a fully distributed architecture across three cities, we break down what works, what doesn’t, and why it matters. Along the way, we cover key concepts like RPO and RTO, failover strategies, and the impact of physical risk factors such as earthquakes or network outages. Whether you’re an engineer building from scratch or a decision-maker planning long-term resilience, this article is designed to help you think strategically before the crisis hits.

Why Database Architecture Matters
In the corporate world, one of the most overlooked yet mission-critical aspects is system architecture. Unfortunately, many organizations still operate under the naive assumption: “Set up a server, install the software, problem solved.” But reality is far more complex. Imagine you’re designing a medical system for patients dependent on life-sustaining devices. You’ve installed the power supply and everything seems to be working. But what happens if the power goes out? Lives could be at risk. That’s why backup power systems are essential. The same applies to databases. If your database crashes or becomes inaccessible, the consequences can be catastrophic impacting not just data, but also time, reputation, and customer trust.
Think Like an Engineer
As engineers, our job isn’t just to “make it work,” but to design systems that are sustainable and resilient. That’s why, at the beginning of every project, we must ask ourselves:
- How many servers do we need?
- Where should they be located?
- Is it enough to have them all in one place?
- What happens if power or connectivity fails?
- How much data loss and downtime is acceptable?
Making infrastructure decisions without answering these questions can lead to costly and irreversible mistakes down the line.
Core Concepts: RPO & RTO
RPO (Recovery Point Objective):
Defines the maximum acceptable data loss window. For instance, “We can tolerate a data loss of up to 5 seconds.” This decision directly influences:
- Synchronous vs. asynchronous replication
- Backup frequency
- Hardware capacity
- And overall cost
It must be a joint decision between technical teams and business units and clearly documented.
RTO (Recovery Time Objective):
Defines how quickly the system should be back online after a failure. For example, “A downtime of no more than 10 minutes is acceptable.” This metric affects:
- The need for automated failover
- The number of replicas
- Disaster recovery planning
Here’s a reference chart showing what different uptime percentages mean in terms of allowable downtime:
| Uptime | Max Monthly Downtime |
| ---------: | --------------------------------- |
| 99% | \~7 hours 18 minutes |
| 99.9% | \~44 minutes |
| 99.99% | \~4 minutes 23 seconds |
| 99.999% | \~26 seconds |
| 99.9999% | \~2.6 seconds |
| 99.99999% | \~0.26 seconds (a quarter second) |Want to go deeper? Read my piece: “Adding Another 9: What’s the Real Cost of High Availability?”
Architectural Choices & Redundant Designs
For PostgreSQL high availability, a minimum of three nodes is recommended:
- Primary (Leader)
- Replica (at least one)
- Backup Server
- Witness Node (for quorum)
Scenario 1: Company A Single Data Center Architecture
A small to mid-size business, no need for automatic failover, prefers functionality over high cost.
Location: Istanbul
- 1 Primary Node
- 1 Replica
- 1 Backup
Total Nodes: 3

The architecture of Company A has a simple structure consisting of a primary, a replica and a backup server, located in Istanbul. The biggest advantage of this architecture is that it can be quickly put into operation at a low cost thanks to its simplicity. For small or medium-sized companies, such structures that facilitate operational management, especially in the initial phase, can be quite functional. If the team size is limited or if a system at the minimum viable product (MVP) level is targeted, this architecture can yield good results in the short term. However, this structure also has serious weaknesses. The most fundamental problem is that the entire system is located in a single physical location. A power outage, network problem or natural disaster in Istanbul can disable the entire system. In other words, physical dependency is very high and no recovery mechanism can be activated in the event of any disaster. On the other hand, the structure does not support automatic failover. When the primary node crashes, getting the system back on its feet depends entirely on manual intervention, which can seriously extend the duration of the service outage.
Scenario 2: Company B Distributed, Highly Available Design
Locations: Istanbul, Ankara, Izmir
Goal: ≥99.99% availability, disaster resilience, and high performance
Node Distribution:
| Role | Istanbul | Ankara | Izmir | Explain |
| ---------------- |----------|--------|-------|----------------------------------------|
| Primary (Leader) | + | | | Main traffic node |
| Replica | + | + | + | One in each data center |
| Extra Replica | | + | + | Two in total, one extra per data center|
| Witness | + | + | + | Required for quorum |
| Backup Node | | + | | Centralized backup location |Total Nodes: 11
- 1 Primary
- 5 Replicas
- 3 Witness
- 1 Backup

The architecture deployed across Istanbul, Ankara, and Izmir consists of a total of 11 nodes and is designed to achieve 99.99% availability, offering both high performance and strong disaster resilience. The Primary node in Istanbul handles all write operations, while replica nodes in the other cities help distribute the read load efficiently. This ensures better performance and reduced pressure on the Primary. The presence of Witness nodes in each location enables a quorum mechanism that guarantees automatic leader election in the event of failure, leveraging technologies like etcd or Raft-based consensus. However, inter-city network latency (~10–20 ms) poses a significant challenge to synchronous replication, as every write would have to wait for a response from a remote replica. To mitigate this, replication across distant nodes is typically asynchronous, ensuring speed and availability, while a local replica within the same data center as the Primary can be designated for synchronous replication, balancing data consistency with write performance. The backup node is centrally located in Ankara due to its relatively lower earthquake risk compared to Istanbul and Izmir. Still, for full redundancy, it’s recommended to replicate backup data to another remote or cloud-based location. Overall, this architecture is a robust and scalable solution for geographically distributed deployments, assuming careful engineering and consistent operational oversight.
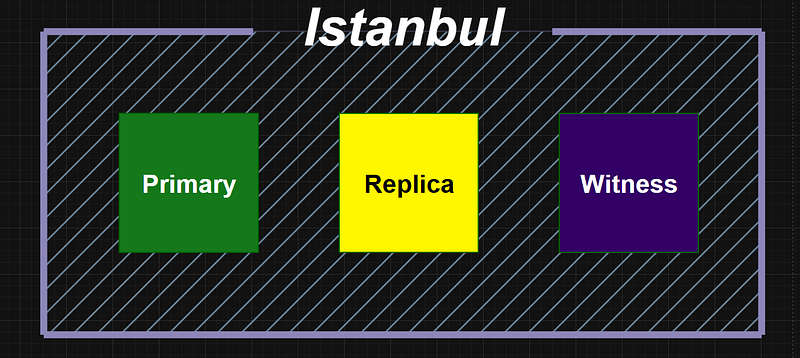
This site serves as the core of the system, hosting the Primary node, which handles all write operations. Additionally, a local replica can be deployed here in synchronous mode, ensuring zero data loss (RPO = 0) if the primary node fails. This is crucial to maintain strong consistency for mission-critical applications. Since this data center bears the brunt of transactional traffic, it must be provisioned with high IOPS storage, redundant power and low-latency internal networking. The presence of a Witness node also contributes to the quorum for failover decisions. However, given Istanbul’s higher seismic risk, it should never be a single point of failure hence the distributed setup.

Ankara functions as a strategic secondary hub and houses both replica nodes and the central backup server. Placing the backup node here is an intentional decision based on Ankara’s relatively lower earthquake exposure, providing a physically safer location for critical data retention. Replicas here operate in asynchronous mode, supporting read scaling and disaster recovery without introducing latency to write operations. Additionally, Ankara includes a Witness node to support quorum-based leader elections. This site could also evolve into a promotable failover candidate, given its balanced geographic and infrastructural positioning.
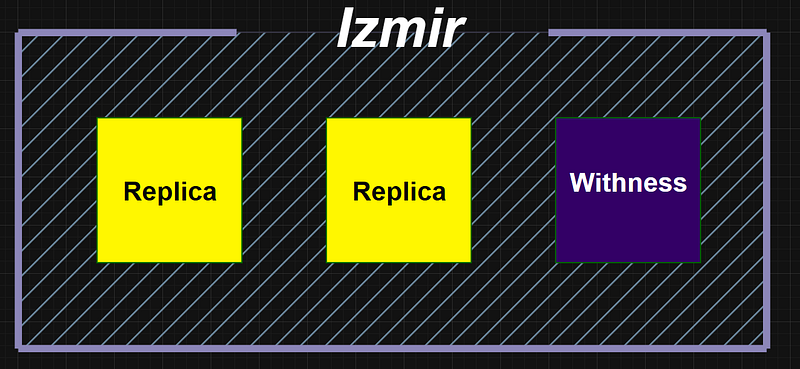
Izmir complements the architecture with replica nodes and a witness node, reinforcing both availability and quorum reliability. Although not selected based on ideal geography, Izmir was included in the simulation due to its network proximity to Ankara and the need for regional diversity. Its two replica nodes support read scalability and ensure the system remains functional even if both Istanbul and Ankara face outages. Future enhancements might include evaluating other regions or cloud regions with better geopolitical and infrastructural advantages. In its current form, Izmir still plays a vital role in multi-region fault tolerance.
Everything You Don’t Design Today Becomes a Problem Tomorrow
In database systems, it’s not just the initial setup that matters it’s the long-term sustainability that truly defines success. Without the right architecture, a solid backup strategy, and a well-defined business continuity plan, the entire system can collapse when a crisis hits. Remember, good engineering isn’t just about getting the system online it’s about ensuring it never becomes unrecoverable. If you’d like to analyze your company’s architecture or start building your own PostgreSQL HA setup, feel free to join the conversation in the comments or follow along as we continue to explore this series in upcoming posts.